【ChatGPT画像生成】Image2で超進化した5つの変化|日本語テキストもThinkingモードも実用レベルに

AI画像生成って、試してみたことありますか?
「面白そうで試したけど、日本語がうまく入らなかった」「細かい指示を出しても、なんか違う画像が出てきた」「テキストが崩れてポスターどころか使い物にならなかった」
そんな体験が重なって、「AI画像生成は趣味の人がやるもの」「プロのデザイナーが使うもの」と感じていた方も多いと思います。
私もそうでした。画像生成AIには何度か挑戦したけれど、毎回「惜しいな…」で終わっていました。
でも2026年4月21日にリリースされた「ChatGPT Images 2.0(GPT-Image-2)」を触ったとき、正直驚きました。
「これ、本当に使えるじゃないか」と思えた初めての画像生成AIかもしれません。
この記事では、ChatGPT Image2が何をどこまで変えたのかを、具体例と一緒に解説します。「また新機能の紹介記事か」と思わず読み進めてほしいです。今回は本当に次元が違います。
【問題の本質】「AI画像生成は使えない」は正しかった。でも今は違う
「AI画像生成が使えない」と感じてきたのは、あなたのスキルが低いからじゃないんです。
単純な話で、ツール側が実務水準に達していなかっただけです。
これまでの画像生成AI(DALL-E 3など)は「拡散モデル」という仕組みで動いていました。ノイズから画像を作り上げていくプロセスで、見た目の「それっぽさ」は作れても、文字の正確さや指示の細かな反映には限界がありました。
特に日本語ユーザーには厳しかった。画像の中に日本語テキストを入れようとすると、ほぼ確実に崩れる。細かいレイアウト指示は無視される。「自分の思い通りにならない道具」という印象がついてしまっていました。
ChatGPT Image2は、この根本から変わっています。モデルのアーキテクチャが変わり、「考えてから描く」という全く新しいアプローチになりました。
ところが、このImege2の画像生成AIを使ってみると、まったくの別物でした。技術の進歩をこれほど肌で感じたのは久しぶりです。
【原因3つ】以前の画像生成でよく詰まった3つのポイント
原因① テキストが「絵のパーツ」として扱われていた
「日本語テキスト入りの画像が、AI画像生成に最も向かないジャンルだと思っていました」
実際に「開店中」「ご案内」「STEP 1」みたいな文字を画像に入れようとすると、ほぼ毎回崩れる。特に漢字・ひらがなは英字よりさらに難しかった。
原因② 長い指示ほど「途中が消える」
「左上に小さなロゴ、右側に人物、背景は白、フォントはゴシック系で…」と細かく指定しても、どこかが無視される。指示が長くなるほど反映される要素が減っていく、という逆転現象がありました。
「プロンプトを丁寧に書けば書くほど、むしろ崩れやすくなる」という謎の体験をしている人は多いはず。
原因③ 日本語ユーザーは最初からハンディキャップがあった
画像生成AIの多くは英語圏向けに最適化されています。日本語での指示精度、日本語テキストの描画品質、日本的なデザイン文化への対応——これらが圧倒的に不足していました。

【解決方法】ChatGPT Image2が変えた5つのこと
2025年3月に「GPT-4o Image Generation」として大幅アップデートがあり、そして2026年4月21日に「ChatGPT Images 2.0(GPT-Image-2)」として次のステージに進みました。何が変わったのか、実用目線で整理します。
① Thinkingモード:「考えてから描く」
最大の進化がここです。
従来の画像生成AIは「プロンプトを受け取ったら即座に生成開始」でした。ChatGPT Image2は違います。生成前にプロンプトを理解し、構図を計画し、必要があればWeb検索まで行ってから描き始めます。
「先に考えてから描く」というプロセスが加わっただけで、完成度が圧倒的に変わります。
実際に複雑なレイアウトを指示してみると、以前なら何度調整しても崩れていたものが、一発でかなり近い形で出てきました。
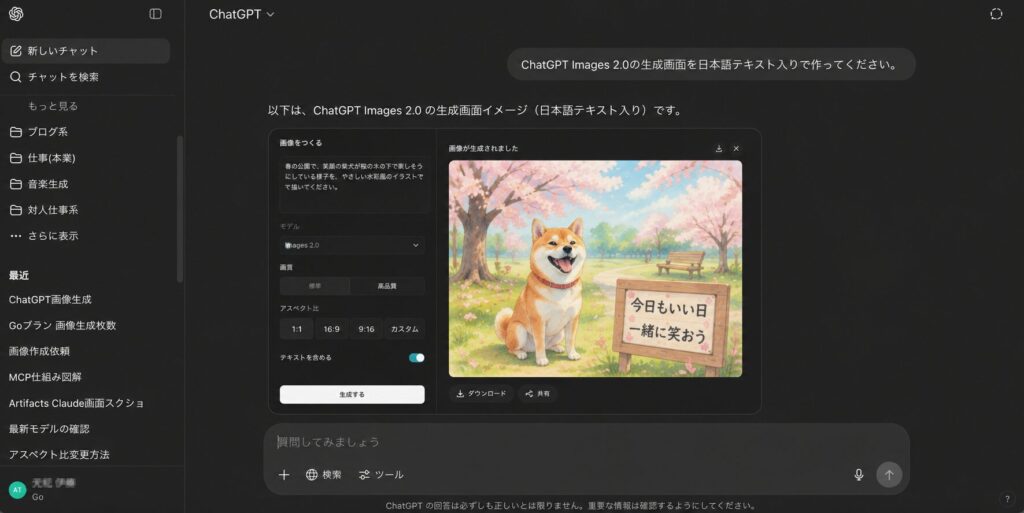
② 日本語テキストが実用レベルで正確に入る
日本語・韓国語・中国語・ヒンディー語などの非ラテン文字が、画像の中に正確に描画されるようになりました。
「日本語ユーザーはやっとスタートラインに立てた」という感覚です。
たとえばこんな使い方ができるようになりました。
- 業務用のお知らせバナー(「〇月〇日 臨時休業」)
- 研修スライドの挿絵(「STEP 1: まず確認する」のような説明図)
- SNS投稿用のテキスト入り画像
以前はこれらをCanvaやPowerPointで手作業していたんですが、ChatGPTへの指示一発で作れるようになっています。

③ 複数画像を「一貫性を保ったまま」同時生成
最大8枚の画像を1回の指示で生成でき、しかもキャラクターやスタイルの統一性が保たれます。
「スタイルが揃ったビジュアルセットを、非デザイナーが作れる」時代になりました。
SNSの投稿用画像、プレゼン資料の挿絵、ブログのアイキャッチ画像シリーズ——こういった「揃っているとプロっぽく見える」コンテンツの制作コストが、劇的に下がりました。
④ Web検索と連携して「最新情報ベース」の画像を作れる
Thinkingモード時に、リアルタイムのWeb情報を参照しながら画像を生成できます。
たとえば「最近のSaaSアプリのUIトレンドを反映したダッシュボード画面のモックアップ」という指示でも、現在のトレンドを踏まえたデザインが出てきます。
⑤ 最大2K解像度・自由なアスペクト比
最大2,048ピクセル(APIベータ版では4K)での出力に対応。アスペクト比は3:1から1:3まで指定できます。
さらに生成速度が従来比4倍向上しているため、「試す→調整する→また試す」のサイクルが快適になっています。
【具体アクション】今日から試せる3つのこと
まずは「体感」から始めましょう。長い準備は不要です。
「まず試してみること。それだけで、自分のコンテンツ制作の幅が変わり始めます。」
まとめ:AI画像生成は「実務ツール」の仲間入りをした
ChatGPT Image2(GPT-Image-2)の主な進化ポイントをまとめます。
「使えなかった」のは、ツールがまだ実務水準に達していなかったからです。今は違います。
「試してみる価値が、初めて本当にある画像生成AIが登場した」と感じています。
もしChatGPT Image2を使って「こんなものが作れた」「ここがわからない」という方がいれば、ぜひシェアしてください。一緒に可能性を探っていきましょう。
X(Twitter)@LabCodecra21138 でも日々発信中です。
参考:OpenAI「Introducing 4o Image Generation」(2025年3月)、「ChatGPT Images 2.0」発表(2026年4月21日)
📩 お問い合わせ・ご相談
この記事に関するご質問や、お仕事のご依頼、「自分も試してみたい」というご相談など、お気軽にどうぞ。
同じ立場で AI と向き合っている方からのご連絡をお待ちしています。